Re-posted from: http://www.stochasticlifestyle.com/differentialequations-jl-2-0-state-ecosystem/
In this blog post I want to summarize what we have accomplished with DifferentialEquations’ 2.0 release and detail where we are going next. I want to put the design changes and development work into a larger context so that way everyone can better understand what has been achieved, and better understand how we are planning to tackle our next challenges.
If you find this project interesting and would like to support our work, please star our Github repository. Thanks!
Now let’s get started.
DifferentialEquations.jl 1.0: The Core
Before we start talking about 2.0, let’s understand first what 1.0 was all about. DifferentialEquations.jl 1.0 was about answering a single question: how can we put the wide array of differential equations into one simple and efficient interface. The result of this was the common interface explained in the first blog post. Essentially, we created one interface that could:
- Specify a differential equation problem
- Solve a differential equation problem
- Analyze a differential equation problem
The problem types, solve command, and solution interface were all introduced here as part of the unification of differential equations. Here, most of the work was on developing the core. DifferentialEquations.jl 1.0 was about having the core methods for solving ordinary differential equations, stochastic differential equations, and differential algebraic equations. There were some nice benchmarks to show that our core native solvers were on the right track, even besting well-known Fortran methods in terms of efficiency, but the key of 1.0 was the establishment of this high level unified interface and the core libraries for solving the problems.
DifferentialEquations.jl 2.0: Extended Capabilities
DifferentialEquations.jl 2.0 asked a very unique question for differential equations libraries. Namely, “how flexible can a differential equations solver be?”. This was motivated by an off-putting remark where someone noted that standard differential equations solvers were limited in their usefulness because many of the higher level analyses that people need to do cannot be done with a standard differential equations solver.
So okay, then we won’t be a standard differential equations solver. But what do we need to do to make all of this possible? I gathered a list of things which were considered impossible to do with “blackbox” differential equations solvers. People want to model continuous equations for protein concentrations inside of each cell, but allow the number of cells (and thus the number of differential equations) to change stochastically over time. People want to model multiscale phenomena, and have discontinuities. Some “differential equations” may only be discontinuous changes of discrete values (like in Gillespie models). People want to solve equations with colored noise, and re-use the same noise process in other calculations. People want to solve the same ODE efficiently hundreds of times, and estimate parameters. People want to quantify the uncertainty and the sensitivity of their model. People want their solutions conserve properties like energy.
People want to make simulations of reality moreso than solve equations.
And this became the goal for DifferentialEquations.jl 2.0. But the sights were actually set a little higher. The underlying question was:
How do you design a differential equations suite such that it can have this “simulation engine” functionality, but also such that adding new methods automatically makes the method compatible with all of these features?
That is DifferentialEquations.jl 2.0. the previous DifferentialEquations.jl ecosystem blog post details the strategies we were going to employ to achieve this goal, but let me take a little bit of time to explain the solution that eventually resulted.
The Integrator Interface
The core of the solution is the integrator interface. Instead of just having an interface on the high-level solve command, the integrator interface is the interface on the core type. Everything inside of the OrdinaryDiffEq.jl, StochasticDiffEq.jl, DelayDiffEq.jl packages (will be referred to as the *DiffEq solvers) is actually just a function on the integrator type. This means that anything that the solver can do, you can do by simply having access to the integrator type. Then, everything can be unified by documenting this interface.
This is a powerful idea. It makes development easy, since the devdocs just explain what is done internally to the integrator. Adding new differential equations algorithms is now simply adding a new perform_step dispatch. But this isn’t just useful for development, this is useful for users too. Using the integrator, you can step one at a time if you wanted, and do anything you want between steps. Resizing the differential equation is now just a function on the integrator type since this type holds all of the cache variables. Adding discontinuities is just changing integrator.u.
But the key that makes this all work is Julia. In my dark past, I wrote some algorithms which used R’s S3 objects, and I used objects in numerical Python codes. Needless to say, these got in the way of performance. However, the process of implementing the integrator type was a full refactor from straight loops to the type format. The result was no performance loss (actually, there was a very slight performance gain!). The abstraction that I wanted to use did not have a performance tradeoff because Julia’s type system optimized its usage. I find that fact incredible.
But back to the main story, the event handling framework was re-built in order to take full advantage of the integrator interface, allowing the user to directly affect the integrator. This means that doubling the size of your differential equation the moment some value hits 1 is now a possibility. It also means you can cause your integration to terminate when “all of the bunnies” die. But this became useful enough that you might not want to just use it for traditional event handling (aka cause some effect when some function hits zero, which we call the ContinuousCallback), but you may just want to apply some affect after steps. The DiscreteCallback allows one to check a boolean function for true/false, and if true apply some function to the integrator. For example, we can use this to always apply a projection to a manifold at the end of each step, effectively preserving the order of the integration while also conserving model properties like energy or angular momentum.
The integrator interface and thus its usage in callbacks then became a way that users could add arbitrary functionality. It’s useful enough that a DiscreteProblem (an ODE problem with no ODE!) is now a thing. All that is done is the discrete problem walks through the ODE solver without solving a differential equation, just hitting callbacks.
But entirely new sets of equations could be added through callbacks. For example, discrete stochastic equations (or Gillespie simulations) are models where rate equations determine the time to the next discontinuity or “jump”. The JumpProblem types simply add callbacks to a differential (or discrete) equation that perform these jumps at specific rates. This effectively turns the “blank ODE solver” into an equation which can solve these models of discrete proteins stochastically changing their levels over time. In addition, since it’s built directly onto the differential equations solvers, mixing these types of models is an instant side effect. These models which mix jumps and differential equations, such as jump diffusions, were an immediate consequence of this design.
The design of the integrator interface meant that dynamicness of the differential equation (changing the size, the solver options, or any other property in the middle of solving) was successfully implemented, and handling of equations with discontinuities directly followed. This turned a lot of “not differential equations” into “models and simulations which can be handled by the same DifferentialEquations.jl interface”.
Generic algorithms over abstract types
However, the next big problem was being able to represent a wider array of models. “Models and simulations which do weird non-differential equation things over time” are handled by the integrator interface, but “weird things which aren’t just a system of equations which do weird non-differential equation things over time” were still out of reach.
The solution here is abstract typing. The *DiffEq solvers accept two basic formats. Let’s stick to ODEs for the explanation. For ODEs, there is the out-of-place format
du = f(t,u)
where the derivative/change is returned by the function, and there is the in-place format
f(t,u,du)
where the function modifies the object du which stores the derivative/change. Both of these formats were generalized to the extreme. In the end, the requirements for a type to work in the out-of-place format can be described as the ability to do basic arithmetic (+,-,/,*), and you add the requirement of having a linear index (or simply having a broadcast! function defined) in order to satisfy the in-place format. If the method is using adaptivity, the user can pass an appropriate norm function to be used for calculating the norm of the error estimate.
This means that wild things work in the ODE solvers. I have already demonstrated arbitrary precision numbers, and unit-checked arithmetic.
But now there’s even crazier. Now different parts of your equation can have different units using the ArrayPartition. You can store and update discrete values along with your differential equation using the DEDataArray type. Just the other day I showed this can be used to solve problems where the variable is actually a symbolic mathematical expression. We are in the late stages of getting a type which represents a spectral discretization of a function compatible with the *DiffEq solvers.
But what about those “purely scientific non-differential equations” applications? A multiscale model of an embryo which has tissues, each with different populations of cells, and modeling the proteins in each cell? That’s just a standard application of the AbstractMultiScaleArray.
Thus using the abstract typing, even simulations which don’t look like systems of equations can now be directly handled by DifferentialEquations.jl. But not only that, since this is done simply via Julia’s generic programming, this compatibility is true for any of the new methods which are added (one caveat: if they use an external library like ForwardDiff.jl, their compatibility is limited by the compatibility of that external library).
Refinement of the problem types
The last two big ideas made it possible for a very large set of problems to be written down as a “differential equation on an array” in a much expanded sense of the term. However, there was another design problem to solve: not every algorithm could be implemented with “the information” we had! What I mean by “information”, I mean the information we could get from the user. The ODEProblem type specified an ODE as

but some algorithms do special things. For example, for the ODE

the Lawson-Euler algorithm for solving the differential equation is

This method exploits the fact that it knows that the first part of the equation is  for some matrix, and uses it directly to improve the stability of the algorithm. However, if all we know is
for some matrix, and uses it directly to improve the stability of the algorithm. However, if all we know is  , we could never implement this algorithm. This would violate our goal of “full flexibility at full performance” if this algorithm was the most efficient for the problem!
, we could never implement this algorithm. This would violate our goal of “full flexibility at full performance” if this algorithm was the most efficient for the problem!
The solution is to have a more refined set of problem types. I discussed this a bit at the end of the previous blog post that we could define things like splitting problems. The solution is quite general, where

can be defined using the SplitODEProblem (M being a mass matrix). Then specific methods can request specific forms, like here the linear-nonlinear ODE. Together, the ODE solver can implement this algorithm for the ODE, and that implementation, being part of a *DiffEq solver, will have interpolations, the integrator interface, event handling, abstract type compatibility, etc. all for free. Check out the other “refined problem types”: these are capable of covering wild things like staggered grid PDE methods and symplectic integrators.
In addition to specifying the same equations in new ways, we created avenues for common analyses of differential equations which are not related to simulating them over time. For example, one common problem is to try to find steady states, or points where the differential equation satisfies  . This can now easily be done by defining a SteadyStateProblem from an ODE, and then using the steady state solver. This new library will also lead to the implementation of accelerated methods for finding steady states, and the development of new accelerated methods. The steady state behavior can now also be analyzed using the bifurcation analysis tools provided by the wrapper to PyDSTool.
. This can now easily be done by defining a SteadyStateProblem from an ODE, and then using the steady state solver. This new library will also lead to the implementation of accelerated methods for finding steady states, and the development of new accelerated methods. The steady state behavior can now also be analyzed using the bifurcation analysis tools provided by the wrapper to PyDSTool.
Lastly, the problem types themselves have become much more expressive. In addition to solving the standard ODE, one can specify mass matrices in any appropriate DE type, to instead solve the equation

where  is some linear operator (similarly in DDEs and SDEs). While the vast majority of solvers are not able to use right now, this infrastructure is there for algorithms to support it. In addition, one can now specify the noise process used in random and stochastic equations, allowing the user to solve problems with colored noise. Using the optional fields, a user can define non-diagonal noise problems, and specify sparse noise problems using sparse matrices.
is some linear operator (similarly in DDEs and SDEs). While the vast majority of solvers are not able to use right now, this infrastructure is there for algorithms to support it. In addition, one can now specify the noise process used in random and stochastic equations, allowing the user to solve problems with colored noise. Using the optional fields, a user can define non-diagonal noise problems, and specify sparse noise problems using sparse matrices.
As of now, only some very basic methods using all of this infrastructure have been made for the most extreme examples for testing purposes, but these show that the infrastructure works and this is ready for implementing new methods.
Common solve extensions
Okay, so once we can specify efficient methods for weird models which evolve over time in weird ways, we can simulate and get what solutions look like. Great! We have a tool that can be used to get solutions! But… that’s only the beginning of most analyses!
Most of the time, we are simulating solutions to learn more about the model. If we are modeling chemical reactions, what is the reaction rate that makes the model match the data? How sensitive is our climate model to our choice of the albedo coefficient?
To back out information about the model, we rely on analysis algorithms like parameter estimation and sensitivity analysis. However, the common solve interface acts as the perfect level for implementing these algorithms because they can be done problem and algorithm agnostic. I discuss this in more detail in a previous blog post, but the general idea is that most of these algorithms can be written with a term  which is the solution of a differential equation. Thus we can write the analysis algorithms at a very high level and allow the user to pass in the arguments for a solve command use that to generate the . The result is an implementation of the analysis algorithm which works with any of the problems and methods which use the common interface. Again, chaining all of the work together to get one more complete product. You can see this in full force by looking at the parameter estimation docs.
which is the solution of a differential equation. Thus we can write the analysis algorithms at a very high level and allow the user to pass in the arguments for a solve command use that to generate the . The result is an implementation of the analysis algorithm which works with any of the problems and methods which use the common interface. Again, chaining all of the work together to get one more complete product. You can see this in full force by looking at the parameter estimation docs.
Modeling Tools
In many cases one is solving differential equations not for their own sake, but to solve scientific questions. To this end, we created a framework for modeling packages which make this easier. The financial models make it easy to specify common financial equations, and the biological models make it easy to specify chemical reaction networks. This functionality all works on the common solver / integrator interface, meaning that models specified in these forms can be used with the full stack and analysis tools. Also, I would like to highlight BioEnergeticFoodWebs.jl as a great modeling package for bio-energetic food web models.
Over time, we hope to continue to grow these modeling tools. The financial tools I hope to link with Julia Computing’s JuliaFin tools (Miletus.jl) in order to make it easy to efficiently solve the SDE and PDE models which result from their financial DSL. In addition, DiffEqPhysics.jl is planned to make it easy to specify the equations of motion just by giving a Hamiltonian or Lagrangian, or by giving the the particles + masses and automatically developing a differential equation. I hope that we can also tackle domains like mechanical systems and pharmacokinetics/pharmacodynamics to continually expand what is easily able to be solved using this infrastructure.
DifferentialEquations 2.0 Conclusion
In the end, DifferentialEquations 2.0 was about finding the right infrastructure such that pretty much anything CAN be specified and solved efficiently. While there were some bumps along the road (that caused breaking API changes), I believe we came up with a very good solution. The result is a foundation which feeds back onto itself, allowing projects like parameter estimation of multiscale models which change size due to events to be standard uses of the ODE solver.
And one of the key things to note is that this follows by design. None of the algorithms were specifically written to make this work. The design of the *DiffEq packages gives interpolation, event handling, compatibility with analysis tools, etc. for free for any algorithm that is implemented in it. One contributor, @ranocha, came to chat in the chatroom and on a few hours later had implemented 3 strong stability preserving Runge-Kutta methods (methods which are efficient for hyperbolic PDEs) in the *DiffEq solvers. All of this extra compatibility followed for free, making it a simple exercise. And that leads me to DifferentialEquations 3.0.
DifferentialEquations 3.0: Stiff solvers, parallel solvers, PDEs, and improved analysis tools
1.0 was about building the core. 2.0 was about making sure that the core packages were built in a way that could be compatible with a wide array of problems, algorithms, and analysis tools. However, in many cases, only the simplest of each type of algorithm was implemented since this was more about building out the capabilities than it was to have completeness in each aspect. But now that we have expanded our capabilities, we need to fill in the details. These details are efficient algorithms in the common problem domains.
Stiff solvers
Let’s start by talking about stiff solvers. As of right now, we have the all of the standard solvers (CVODE, LSODA, radau) wrapped in the packages Sundials.jl, LSODA.jl, and ODEInterface.jl respectively. These can all be used in the DifferentialEquations.jl common interface, meaning that it’s mostly abstracted away from the user that these aren’t actually Julia codes. However, these lower level implementations will never be able to reach the full flexibility of the native Julia solvers simply because they are restricted in the types they use and don’t fully expose their internals. This is fine, since our benchmarks against the standard Runge-Kutta implementations (dopri5, dop853) showed that the native Julia solvers, being more modern implementations, can actually have performance gains over these older methods. But, we need to get our own implementations of these high order stiff solvers.
Currently there exists the Rosenbrock23 method. This method is similar to the MATLAB ode23s method (it is the Order 2/3 Shampine-Rosenbrock method). This method is A and L stable, meaning it’s great for stiff equations. This was thus used for testing event handling, parameter estimation, etc.’s capabilities and restrictions with the coming set of stiff solvers. However, where it lacks is order. As an order 2 method, this method is only efficient at higher error tolerances, and thus for “standard tolerances” it tends not to be competitive with the other methods mentioned before. That is why one of our main goals in DiffEq 3.0 will be the creation of higher order methods for stiff equations.
The main obstacle here will be the creation of a library for making the differentiation easier. There are lots of details involved here. Since a function defined using the macros of ParameterizedFunctions can symbolically differentiate the users function, in some cases a pre-computed function for the inverted or factorized Jacobian can be used to make a stiff method explicit. In other cases, we need autodifferentiation, and in some we need to use numerical differentiation. This is all governed by a system of traits setup behind the scenes, and thus proper logic for determining and using Jacobians can immensely speed up our calculations.
The Rosenbrock23 method did some of this ad-hocly within its own method, but it was determined that the method would be greatly simplified if there was some library that could handle this. In fact, if there was a library to handle this, then the Rosenbrock23 code for defining steps would be as simple as defining steps for explicit RK methods. The same would be true for implicit RK methods like radau. Thus we will be doing that: building a library which handles all of the differentiation logic. The development of this library, DiffEqDiffTools.jl, is @miguelraz ‘s Google Summer of Code project. Thus with the completion of this project (hopefully summer?), efficient and fully compatible high order Rosenbrock methods and implicit RK methods will easily follow. Also included will be additive Runge-Kutta methods (IMEX RK methods) for SplitODEProblems. Since these methods double as native Julia DAE solvers and this code will make the development of stiff solvers for SDEs, this will be a major win to the ecosystem on many fronts.
Stiffness Detection and Switching
In many cases, the user may not know if a problem is stiff. In many cases, especially in stochastic equations, the problem may be switching between being stiff and non-stiff. In these cases, we want to change the method of integration as we go along. The general setup for implementing switching methods has already been implemented by the CompositeAlgorithm. However, current usage of the CompositeAlgorithm requires that the user define the switching behavior. This makes it quite difficult to use.
Instead, we will be building methods which make use of this infrastructure. Stiffness detection estimates can be added to the existing methods (in a very efficient manner), and could be toggled on/off. Then standard switching strategies can be introduced such that the user can just give two algorithms, a stiff and a non-stiff solvers, and basic switching can then occur. What is deemed as the most optimal strategies can then be implemented as standard algorithm choices. Then at the very top, these methods can be added as defaults for solve(prob), making the fully automated solver efficiently handle difficult problems. This will be quite a unique feature and is borderline a new research project. I hope to see some really cool results.
Parallel-in-time ODE/BVP solvers
While traditional methods (Runge-Kutta, multistep) all step one time point at a time, in many cases we want to use parallelism to speed up our problem. It’s not hard to buy an expensive GPU, and a lot of us already have one for optimization, so why not use it?
Well, parallelism for solving differential equations is very difficult. Let’s take a look at some quick examples. In the Euler method, the discretization calculates the next time step  from the previous time step
from the previous time step  using the equation
using the equation

In code, this is the update step
u .= uprev .+ dt.*f(t,uprev)
I threw in the .’s to show this is broadcasted over some arrays, i.e. for systems of equations  is a vector. And that’s it, that’s what the inner loop is. The most you can parallelize are the loops internal to the broadcasts. This means that for very large problems, you can parallelize this method efficiently (this form is called parallelism within the method). Also, if your input vector was a GPUArray, this will broadcast using CUDA or OpenCL. However, if your problem is not a sufficiently large vector, this parallelism will not be very efficient.
is a vector. And that’s it, that’s what the inner loop is. The most you can parallelize are the loops internal to the broadcasts. This means that for very large problems, you can parallelize this method efficiently (this form is called parallelism within the method). Also, if your input vector was a GPUArray, this will broadcast using CUDA or OpenCL. However, if your problem is not a sufficiently large vector, this parallelism will not be very efficient.
Similarly for implicit equations, we need to repeatedly solve  where
where  is the Jacobian matrix. This linear solve will only parallelize well if the Jacobian matrix is sufficiently large. But many small differential equations problems can still be very difficult. For example, this about solving a very stiff ODE with a few hundred variables. Instead, the issue is that we are stepping serially over time, and we need to use completely different algorithms which parallelize over time.
is the Jacobian matrix. This linear solve will only parallelize well if the Jacobian matrix is sufficiently large. But many small differential equations problems can still be very difficult. For example, this about solving a very stiff ODE with a few hundred variables. Instead, the issue is that we are stepping serially over time, and we need to use completely different algorithms which parallelize over time.
One of these approaches is a collocation method. Collocation methods build a very large nonlinear equation  which describes a numerical method over all time points at once, and simultaneously solves for all of the time points using a nonlinear solver. Internally, a nonlinear solver is just a linear solver,
which describes a numerical method over all time points at once, and simultaneously solves for all of the time points using a nonlinear solver. Internally, a nonlinear solver is just a linear solver,  , with a very large . Thus, if the user passes in a custom linear solver method, say one using PETSc.jl or CUSOLVER, this is parallelize efficiently over many nodes of an HPC or over a GPU. In fact, these methods are the standard methods for Boundary Value Problems (BVPs). The development of these methods is the topic of @YingboMa’s Google Summer of Code project. While written for BVPs, these same methods can then solve IVPs with a small modification (including stochastic differential equations).
, with a very large . Thus, if the user passes in a custom linear solver method, say one using PETSc.jl or CUSOLVER, this is parallelize efficiently over many nodes of an HPC or over a GPU. In fact, these methods are the standard methods for Boundary Value Problems (BVPs). The development of these methods is the topic of @YingboMa’s Google Summer of Code project. While written for BVPs, these same methods can then solve IVPs with a small modification (including stochastic differential equations).
By specifying an appropriate preconditioner with the linear solver, these can be some of the most efficient parallel methods. When no good preconditioner is found, these methods can be less efficient. One may wonder then if there’s exists a different approach, one which may sacrifice some “theoretical top performance” in order to be better in the “low user input” case (purely automatic). There is! Another approach to solving the parallelism over time issue is to use a neural network. This is the topic of @akaysh’s Google Summer of Code project. Essentially, you can define a cost function which is the difference between the numerical derivative and  at each time point. This then gives an optimization problem: find the
at each time point. This then gives an optimization problem: find the  at each time point such that the difference between the numerical and the desired derivatives is minimized. Then you solve that cost function minimization using a neural network. The neat thing here is that neural nets are very efficient to parallelize over GPUs, meaning that even for somewhat small problems we can get out very good parallelism. These neural nets can use very advanced methods from packages like Knet.jl to optimize efficiently and parallel with very little required user input (no preconditioner to set). There really isn’t another standard differential equations solver package which has a method like this, so it’s hard to guess how efficient it will be in advance. But given the properties of this setup, I suspect this should be a very good “automatic” method for medium-sized (100’s of variables) differential equations.
at each time point such that the difference between the numerical and the desired derivatives is minimized. Then you solve that cost function minimization using a neural network. The neat thing here is that neural nets are very efficient to parallelize over GPUs, meaning that even for somewhat small problems we can get out very good parallelism. These neural nets can use very advanced methods from packages like Knet.jl to optimize efficiently and parallel with very little required user input (no preconditioner to set). There really isn’t another standard differential equations solver package which has a method like this, so it’s hard to guess how efficient it will be in advance. But given the properties of this setup, I suspect this should be a very good “automatic” method for medium-sized (100’s of variables) differential equations.
The really great thing about these parallel-in-time methods is that they are inherently implicit, meaning that they can be used even on extremely stiff equations. There are also simple extensions to make these solver SDEs and DDEs. So add this to the bank of efficient methods for stiff diffeqs!
Improved methods for stochastic differential equations
As part of 3.0, the hope is to release brand new methods for stochastic differential equations. These methods will be high order and highly stable, some explicit and some implicit, and will have adaptive timestepping. This is all of the details that I am giving until these methods are published, but I do want to tease that many types of SDEs will become much more efficient to solve.
Improved methods for jump equations
For jump equations, in order to show that everything is complete and can work, we have only implemented the Gillespie method. However, we hope to add many different forms of tau-leaping and Poisson(/Binomial) Runge-Kutta methods for these discrete stochastic equations. Our roadmap is here and it seems there may be a great deal of participation to complete this task. Additionally, we plan on having a specialized DSL for defining chemical reaction networks and automatically turn them into jump problems or ODE/SDE systems.
Geometric and symplectic integrators
In DifferentialEquations.jl 2.0, the ability to Partitioned ODEs for dynamical problems (or directly specify a second order ODE problem) was added. However, only a symplectic Euler method has been added to solve this equations so far. This was used to make sure the *DiffEq solvers were compatible with this infrastructure, and showed that event handling, resizing, parameter estimation, etc. all works together on these new problem types. But, obviously we need more algorithms. Velocity varlet and higher order Nystrom methods are asking to be implemented. This isn’t difficult for the reasons described above, and will be a very nice boost to DifferentialEquations.jl 3.0.
(Stochastic/Delay) Partial differential equations
Oh boy, here’s a big one. Everyone since the dawn of time has wanted me to focus on building a method that makes solving the PDE that they’re interested dead simple to do. We have a plan for how to get there. The design is key: instead of one-by-one implementing numerical methods for each PDE, we needed a way to pool the efforts together and make implementations on one PDE matter for other PDEs.
Let’s take a look at how we can do this for efficient methods for reaction-diffusion equations. In this case, we want to solve the equation

The first step is always to discretize this over space. Each of the different spatial discretization methods (finite difference, finite volume, finite element, spectral), end up with some equation

where now  is a vector of points in space (or discretization of some basis). At this point, a specialized numerical method for stepping this equation efficiently in the time can be written. For example, if diffusion is fast and is stiff, one really efficient method is the implicit integrating factor method. This would solve the equation by updating time points like:
is a vector of points in space (or discretization of some basis). At this point, a specialized numerical method for stepping this equation efficiently in the time can be written. For example, if diffusion is fast and is stiff, one really efficient method is the implicit integrating factor method. This would solve the equation by updating time points like:

where we have to solve this implicit equation each time step. The nice thing is that the implicit equation decouples in space, and so we actually only need to solve a bunch of very small implicit equations.
How can we do this in a way that is not “specific to the heat equation”? There were two steps here, the first is discretizing in space, the second is writing an efficient method specific to the PDE. The second part we already have an answer for: this numerical method can be written as one of the methods for linear/nonlinear SplitODEProblems that we defined before. Thus if we just write a SplitODEProblem algorithm that does this form of updating, it can be applied to any ODE (and any PDE discretization) which splits out a linear part. Again, because it’s now using the ODE solver, all of the extra capabilities (event handling, integrator interface, parameter estimation tools, interpolations, etc.) all come for free as well. The development of ODE/SDE/DDE solvers for handling this split, like implicit integrating factor methods and exponential Runge-Kutta methods, is part of DifferentialEquations.jl 3.0’s push for efficient (S/D)PDE solvers.
So with that together, we just need to solve the discretization problem. First let’s talk about finite difference. For the Heat Equation with a fixed grid-size  , many people know what the second-order discretization matrix is in advance. However, what if you have variable grid sizes, and want different order discretizations of different derivatives (say a third derivative)? In this case the Fornburg algorithm can be used to construct this . And instead of making this an actual matrix, because this is sparse we can make this very efficient by creating a “matrix-free type” where
, many people know what the second-order discretization matrix is in advance. However, what if you have variable grid sizes, and want different order discretizations of different derivatives (say a third derivative)? In this case the Fornburg algorithm can be used to construct this . And instead of making this an actual matrix, because this is sparse we can make this very efficient by creating a “matrix-free type” where  acts like the appropriate matrix multiplication, but in reality no matrix is ever created. This can save a lot of memory and make the multiplication a lot more efficient by ignoring the zeros. In addition, because of the reduced memory requirement, we easily distribute this operator to the GPU or across the cluster, and make the function utilize this parallelism.
acts like the appropriate matrix multiplication, but in reality no matrix is ever created. This can save a lot of memory and make the multiplication a lot more efficient by ignoring the zeros. In addition, because of the reduced memory requirement, we easily distribute this operator to the GPU or across the cluster, and make the function utilize this parallelism.
The development of these efficient linear operators is the goal of @shivin9’s Google Summer of Code project. The goal is to get a function where the user can simply specify the order of the derivative and the order of the discretization, and it will spit out this highly efficient to be used in the discretization, turning any PDE into a system of ODEs. In addition, other operators which show up in finite difference discretizations, such as the upwind scheme, can be encapsulated in such an . Thus this project would make turning these types of PDEs into efficient ODE discretizations much easier!
The other very popular form of spatial discretization is the finite element method. For this form, you chose some basis function over space and discretize the basis function. The definition of this basis function’s discretization then derives what the discretization of the derivative operators should be. However, there is a vast array of different choices for basis and the discretization. If we wanted to create a toolbox which would implement all of what’s possible, we wouldn’t get anything else done. Thus we will instead, at least for now, piggyback off of the efforts of FEniCS. FEniCS is a toolbox for the finite element element method. Using PyCall, we can build an interface to FEniCS that makes it easy to receive the appropriate linear operator (usually sparse matrix) that arises from the desired discretization. This, the development of a FEniCS.jl, is the topic of @ysimillides’s Google Summer of Code. The goal is to make this integration seamless, so that way getting ODEs out for finite element discretizations is a painless process, once again reducing the problem to solving ODEs.
The last form of spatial discretization is spectral discretizations. These can be handled very well using the Julia library ApproxFun.jl. All that is required is to make it possible to step in time the equations which can be defined using the ApproxFun types. This is the goal of DiffEqApproxFun.jl. We already have large portions of this working, and for fixed basis lengths the ApproxFunProblems can actually be solved using any ODE solver (not just native Julia solvers, but also methods from Sundials and ODEInterface work!). This will get touched up soon and will be another type of PDE discretization which will be efficient and readily available.
Improved Analysis Tools
What was described above is how we are planning to solve very common difficult problems with high efficiency and simplify the problems for the user, all without losing functionality. However, the tools at the very top of the stack, the analysis tools, can also become much more efficient as well. This is the other focus of DifferentialEquations.jl 3.0.
Local sensitivity analysis is nice because it not only tells you how sensitive your model is to the choice of parameters, but it gives this information at every time point. However, in many cases this is overkill. Also, this makes the problem much more computationally difficult. If we wanted to classify parameter space, like to answer the question “where is the model least sensitive to parameters?”, we would have to solve this equation many times. When this is the question we wish to answer, global sensitivity analysis methods are much more efficient. We plan on adding methods like the Morris method in order for sensitives to be globally classified.
In addition, we really need better parameter estimation functionality. What we have is very good: you can build an objective function for your parameter estimation problem to then use Optim.jl, BlackBoxOptim.jl or any MathProgBase/JuMP solver (example: NLopt.jl) to optimize the parameters. This is great, but it’s very basic. In many cases, more advanced methods are necessary in order to get convergence. Using likelihood functions instead of directly solving the nonlinear regression can often times be more efficient. Also, in many cases statistical methods (the two-stage method) can be used to approximately optimize parameters without solving the differential equations repeatedly, a huge win for performance. Additionally, Bayesian methods will not only give optimal parameters, but distributions for the parameters which the user can use to quantify how certain they are about estimation results. The development of these methods is the focus of @Ayush-iitkgp’s Google Summer of Code project.
DifferentialEquations.jl 3.0 Conclusion
2.0 was about building infrastructure. 3.0 is about filling out that infrastructure and giving you the most efficient methods in each of the common problem domains.
DifferentialEquations.jl 4.0 and beyond
I think 2.0 puts us in a really great position. We have a lot, and the infrastructure allows us to be able to keep expanding and adding more and more algorithms to handle different problem types more efficiently. But there are some things which are not slated in the 3.0 docket. One thing that keeps getting pushed back is the automatic promotion of problem types. For example, if you specified a SplitODEProblem and you want to use an algorithm which wants an ODEProblem (say, a standard Runge-Kutta algorithm like Tsit5), it’s conceivable that this conversion can be handled automatically. Also, it’s conceivable that since you can directly convert an ODEProblem into a SteadyStateProblem, that the steady state solvers should work directly on an ODEProblem as well. However, with development time always being a constraint, I am planning on spending more time developing new efficient methods for these new domain rather than the automatic conversions. However, if someone else is interested in tackling this problem, this could probably be addressed much sooner!
Additionally, there is one large set of algorithms which have not been addressed in the 3.0 plan: multistep methods. I have been holding off on these for a few reasons. For one, we have wrappers to Sundials, DASKR, and LSODA which supply well-known and highly efficient multistep methods. However, these wrappers, having the internals not implemented in Julia, are limited in their functionality. They will never be able to support arbitrary Julia types and will be constrained to equations on contiguous arrays of Float64s. Additionally, the interaction with Julia’s GC makes it extremely difficult to implement the integrator interface and thus event handling (custom allocators would be needed). Also, given what we have seen with other wrappers, we know we can actually improve the efficiency of these methods.
But lastly, and something I think is important, these methods are actually only efficient in a small but important problem domain. When the ODE is not “expensive enough”, implicit Runge-Kutta and Rosenbrock methods are more efficient. When it’s a discretization of a PDE and there exists a linear operator, exponential Runge-Kutta and implicit integrating factor methods are more efficient. Also, if there are lots of events or other dynamic behavior, multistep methods have to “restart”. This is an expensive process, and so in most cases using a one-step method (any of the previously mentioned methods) is more efficient. This means that multistep methods like Adams and BDF (/NDF) methods are really only the most efficient when you’re talking about a large spatial discretization of a PDE which doesn’t have a linear operator that you can take advantage of and events are non-existent/rare. Don’t get me wrong, this is still a very important case! But, given the large amount of wrappers which handle this quite well already, I am not planning on tackling these until the other parts are completed. Expect the *DiffEq infrastructure to support multistep methods in the future (actually, there’s already quite a bit of support in there, just the adaptive order and adaptive time step needs to be made possible), but don’t count on it in DifferentialEquations 3.0.
Also not part of 3.0 but still of importance is stochastic delay differential equations. The development of a library for handling these equations can follow in the same manner as DelayDiffEq.jl, but likely won’t make it into 3.0 as there are more pressing (more commonly used) topics to address first. In addition, methods for delay equations with non-constant lags (and neutral delay equations) also will likely have to wait for 4.0.
In the planning stages right now is a new domain-specific language for the specification of differential equations. The current DSL, the @ode_def macro in ParameterizedFunctions.jl does great for the problem that it can handle (ODEs and diagonal SDEs). However, there are many good reasons to want to expand the capabilities here. For example, equations defined by this DSL can be symbolically differentiated, leading to extremely efficient code even for stiff problems. In addition, one could theoretically “split the ODE function” to automatically turn the problem in a SplitODEProblem with a stiff and nonstiff part suitable for IMEX solvers. If PDEs also can be written in the same syntax, then the PDEs can be automatically discretized and solved using the tools from 2.0. Additionally, one can think about automatically reducing the index of DAEs, and specifying DDEs.
This all sounds amazing, but it will need a new DSL infrastructure. After a discussion to find out what kind of syntax would be necessary, it seems that a major overhaul of the @ode_def macro would be needed in order to support all of this. The next step will be to provide a new library, DiffEqDSL.jl, for providing this enhanced DSL. As described in the previously linked roadmap discussion, this DSL will likely take a form closer in style to JuMP, and the specs seem to be compatible at reaching the above mentioned goals. Importantly, this will be developed as a new DSL and thus the current @ode_def macro will be unchanged. This is a large development which will most likely not be in 3.0, but please feel free to contribute to the roadmap discussion which is now being continued at the new repository.
Conclusion
DifferentialEquations.jl 1.0 was about establishing a core that could unify differential equations. 2.0 was about developing the infrastructure to tackle a very vast domain of scientific simulations which are not easily or efficiently written as differential equations. 3.0 will be be about producing efficient methods for the most common sets of problems which haven’t adequately addressed yet. This will put the ecosystem in a very good state and hopefully make it a valuable tool for many people. After this, 4.0+ will keep adding algorithms, expand the problem domain some more, and provide a new DSL.
The post DifferentialEquations.jl 2.0: State of the Ecosystem appeared first on Stochastic Lifestyle.







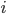

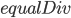





![cudaCores=[2946]](https://i2.wp.com/www.stochasticlifestyle.com/wp-content/plugins/latex/cache/tex_77145979839f0aa461fb95033ff1f5a4.gif)
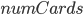

![cudaCores[i]](https://i2.wp.com/www.stochasticlifestyle.com/wp-content/plugins/latex/cache/tex_fcdf951de22da0e6201f3ff421a4614d.gif)