By: Chris G
Re-posted from: https://grollchristian.wordpress.com/2016/06/13/germany-most-likely-to-win-euro-2016/
After World Cup 2014 we finally are facing the next spectacular football event now: Euro 2016. With billions of football fans spread all over the world, football still seems to be the single most popular sport. Might have something to do with the fact that football is a game of underdogs: David could beat Goliath any day. Just take a look at the marvelous story of underdog Leicester City in this year’s Premier League season. It is this high uncertainty in future match outcomes that keeps everybody excited and puzzled about the one question: who is going to win?
A question, of course, that just feels like a perfectly designed challenge for data science, with an ever increasing wealth of football match statistics and other related data that is freely available nowadays. It comes as no surprise, hence, that Euro 2016 also puts statistics and data mining into the spotlight. Next to “who is going to win?”, the second question is: “who is going to make the best forecast?”
Besides the big players of the industry, whose predictions traditionally get the most of the media attention, there also is a less known academic research group that already had remarkable success in forecasting in the past. Andreas Groll and Gunther Schauberger from Ludwig-Maximilians-University, together with Thomas Kneib from Georg-August-University, again did set out to forecast the next Euro champion, after they already were able to predict the champion of Euro 2012 and World Cup 2014 correctly.
Based on publicly available data and the gamlls R-package they built a model to forecast probabilities of win, tie and loss for any game of Euro 2016 (Actually, they even get probabilities on a more precise level with an exact number of goals for both teams. For more details on the model take a look at their preliminary technical report).
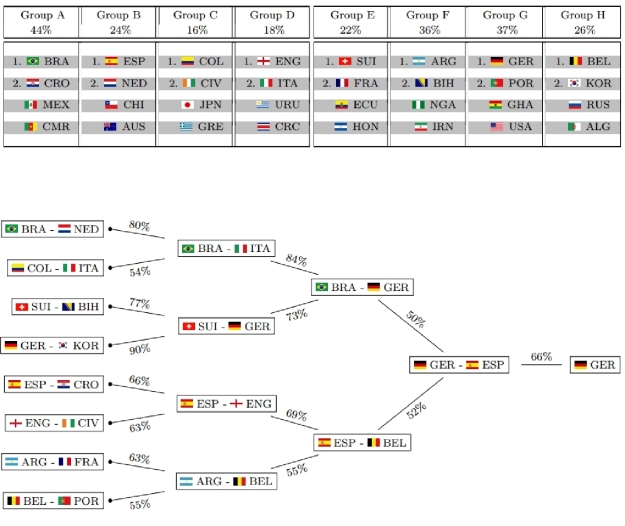
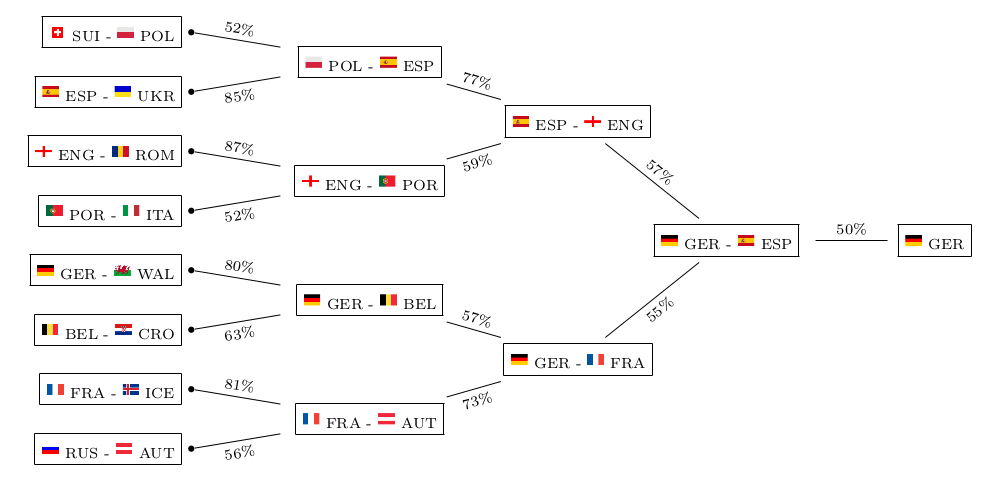
This is what their model deems as most likely tournament evolution this time:
![]()
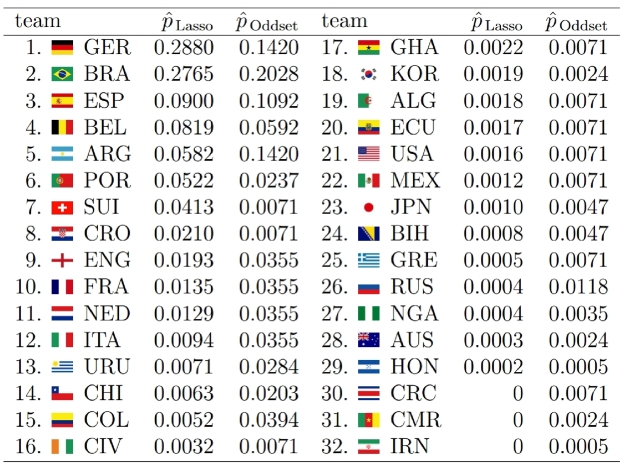
The model not only takes into account individual team strengths, but also the group constellations that were randomly drawn and also have an influence on the tournament’s outcome. This is what their model predicts as probabilities for each team and each possible achievement in the tournament:

So good news for all Germans: after already winning World Cup 2014, “Die Mannschaft” seems to be getting its hands on the next big international football title!
Well, do they? Let’s see…
Mainstream media usually only picks up on the prediction of the Euro champion – the “point forecast”, so to speak. Keep in mind that although this single outcome may well be the most likely one, it still is quite unlikely itself with a probability of 21.1% only. So from a statistical point of view, you basically should not judge the model only on grounds of whether it is able to predict the champion again, as this would require a good portion of luck, too. Just imagine the probability of the most likely champion was 30%, then getting it correctly three times in a row merely has a probability of (0.3)³=0.027 or 2.7%. So in order to really evaluate the goodness of the model you need to check its forecasting power on a number of games and see whether it consistently does a good job, or even outperforms bookmakers’ odds. Although the report does not list the probabilities for each individual game, you still can get a quite good feeling about the goodness of the model, for example, by looking at the predicted group standings and playoff participants. Just compare them to what you would have guessed yourself – who’s the better football expert?