The use of Apache Spark as a distributed data and computation engine has grown rapidly in recent times. Leveraging the Hadoop ecosystem, enterprise workloads have swiftly migrated to Spark. Hosted Spark instances from AWS and Azure have made it even easier to get started, and to run large, on-demand clusters for dynamic workloads.
Scala, the primary language of Spark, is not everyone’s cup of tea when it comes to numeric computing problems. Mostly arising out the JVM, problems include floating point inaccuracy, lack of performance on user defined mathematical constructs, and library support for complex optimisation or linear algebra routines.
Being built for numerical computing, Julia is however perfectly suited to create fast and accurate numerical applications, while leveraging the large scale data handling capabilities of the Spark platform.
Spark.jl
The Spark.jl package, created by Andrei Zhabinsky, with subsequent contributions by a larger worldwide group of developers, enables the use of Julia programs on Spark. It allows you to connect to a Spark cluster from the Julia REP and load data and submit jobs. The typical operating model involves creating a Spark RDD by loading file, or from any Julia iterator. Then, Julia functions can be applied to the RDD using the standard Spark verbs, all from within Julia. This first class integration is enabled via the JavaCall julia package that allow interoperability of Julia and Java codebases.
As an example, a typical session to compute a distributed wordcount (the “Hello World” of distributed computing) from Julia would look like this (all code typed in the Julia REPL)
using Spark
Spark.init()
sc = SparkContext(master="local")
text = parallelize(sc, ["hello world", "the world is one", "we are the world"])
words = flat_map(text, split)
words_tuple = cartesian(words, parallelize(sc, [1]))
counts = reduce_by_key(words_tuple, +)
result = collect(counts)
7-element Array{Any,1}:
("are", 1)
("is", 1)
("one", 1)
("we", 1)
("hello", 1)
("world", 3)
("the", 2)
A second example shows the code to calculate using a simple Monte Carlo method.
NUM_SAMPLES = 10000
samples = parallelize(sc, 1:NUM_SAMPLES)
c = filter(samples, (_)->begin;x=rand(2); x[1]^2 + x[2]^2 <1;end) |> count
print(4 * c / NUM_SAMPLES)
3.1432
It is important to note that in these examples, the core domain calculations are being done in Julia code – in the spilt and + functions of the first example, and in the anonymous function of the second example. In addition however, familiar Spark API functions names such as parallelize/map/reduce/reduce_by_key, are being used to distribute the code and the data to the various Spark nodes that make up the cluster.
A large proportion of the Spark RDD api is accessible from Julia, as well as the beginnings of support for the Dataframes and Spark SQL api. Detailed documentation can be perused at http://dfdx.github.io/Spark.jl/.
Installing and Running
Installing the Julia Spark bindings is as simple as adding the package via the Pkg.add(“Spark.jl”) command from the julia REPL. This will install a local standalone Spark environment for testing, in addition to the Julia bindings. Java and maven are prerequisites, and the latter should be present in the system path.
When running this in a production setting, a Julia process is used as a driver, and it connects to an existing Spark cluster in client mode. Standalone, Mesos and YARN clusters are supported. On the cluster, Julia and it’s dependencies needs to be installed on all nodes. This should be automated, and pre-built scripts are available for the major cloud providers. This makes the cloud hosted Spark clusters provided by Amazon EMR and Azure HDInsight the easiest environments to run this on.
Julia on Azure HDInsight
Creating an HDInsight cluster on Azure is a matter of following the online wizard on the Azure portal. Choose Spark 2.1 on Linux (HDI 3.6) as the cluster type. Default settings can be used for everything else.
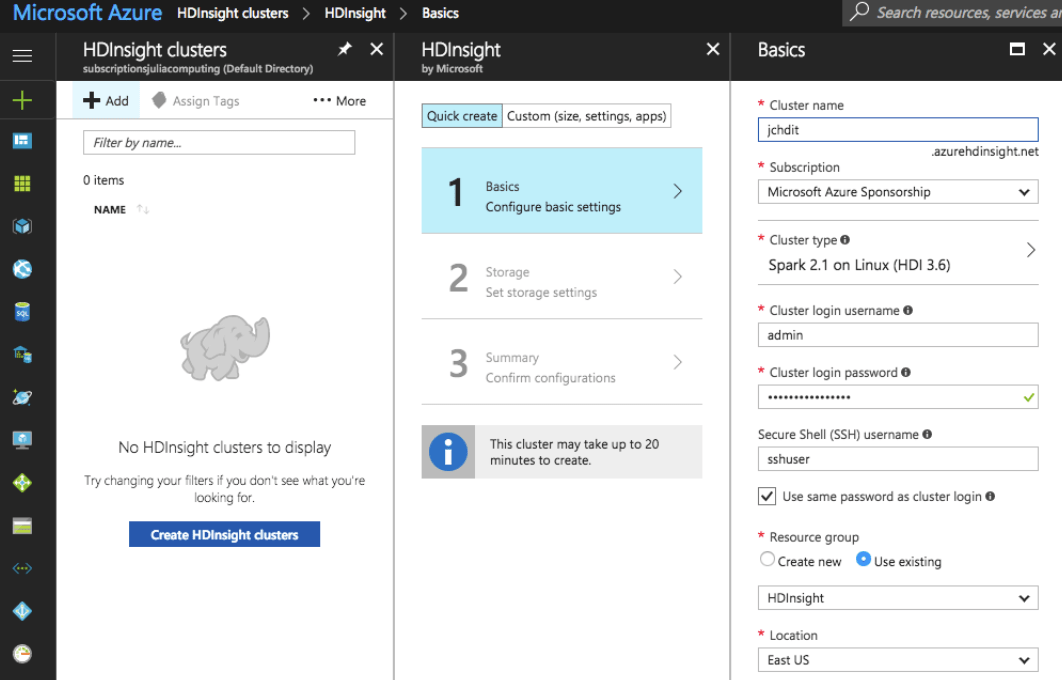
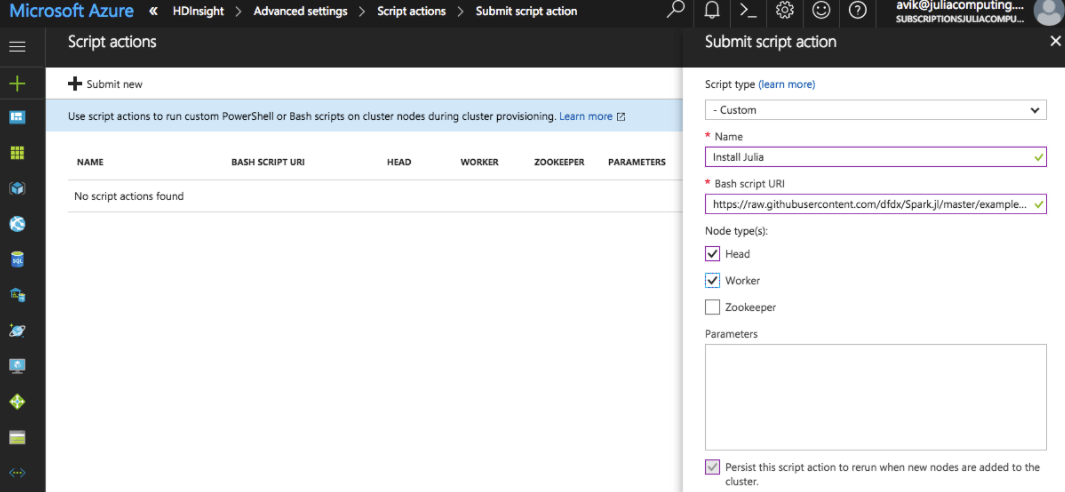
Create an Azure Data Lake Store principal if you intend to load data out of ADL Store. Choose a cluster size based on your requirements. By default HDInsight creates a cluster with 2 master nodes, and 4 workers. One the basic settings are provided, choose to edit the Advanced Settings and configure a script action. You can use the example supplied with the package to create a basic Julia installation on the cluster. For production use, you will want to edit the script to satisfy your requirements, for example adding packages, or installing JuliaPro.
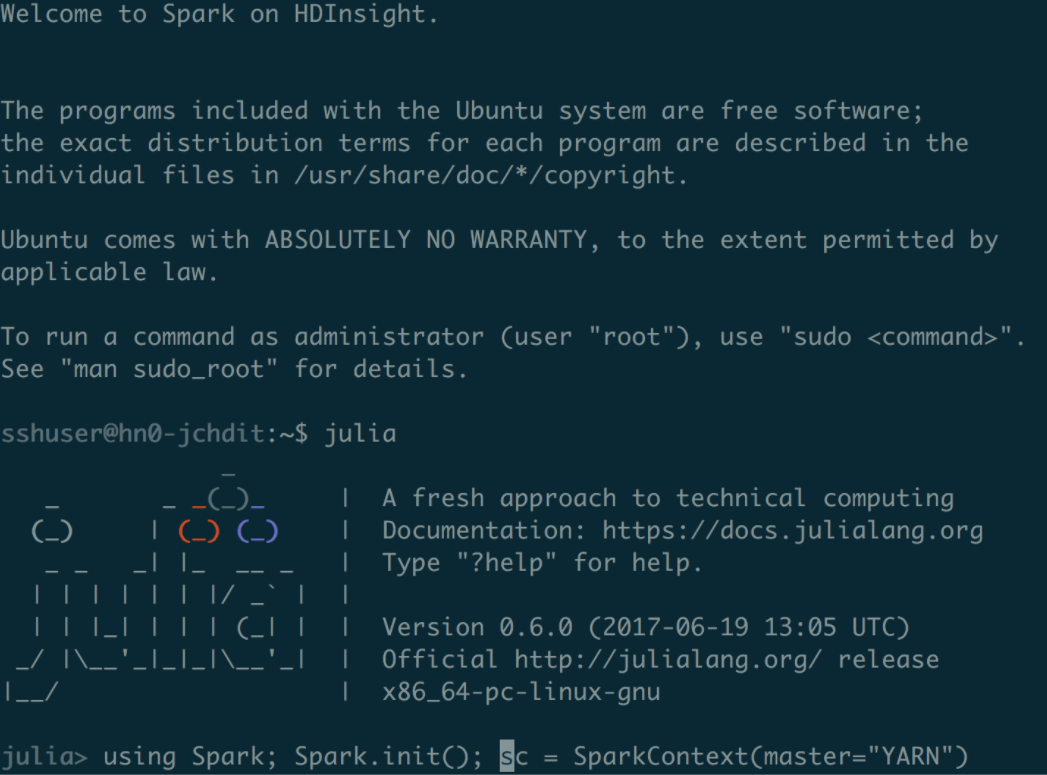
Finally, once the cluster has been created, SSH to the master node, where you will find Julia available on the PATH. The cluster is running using the YARN cluster manager, where all endpoints are configured using property files. As a result, connecting to the cluster from Julia is simply a matter of specifying YARN as the cluster mode.
This post was formatted for the Julia Computing blog by Rajshekar Behar